Vero細胞の物語 ~その樹立からゲノム構造の決定、そして未来へ~
内容
1.日本で生まれたVero細胞
2.何故、私たちはVero細胞の全ゲノム配列を決定しようとしたのか
3.多施設共同研究チームの発足
4.シード細胞の選択
5.核型の解析とは
6.アフリカミドリザルの核型とVero細胞の核型
7.雌ザル由来のVero細胞
8.ゲノム配列解読
9.アフリカミドリザルのゲノム配列公開
10.Vero細胞のゲノム配列解読でわかったこと
(1)Vero細胞はAfrican green monkeysのChlorocebus sabaeusに由来する
(2)ウイルス抑制に働くI型インターフェロン遺伝子クラスターの欠失
(3)細胞周期のブレーキ役の欠失
(4)どのようにして両方の12番相同染色体に欠失ができたのだろうか
(5)Vero細胞系列の確認試験として欠失領域情報を利用する
(6)内在性レトロウイルス配列の多様性
11.今後の展望
12.余談
13.引用文献リスト
Vero細胞の物語 ~その樹立からゲノム構造の決定、そして未来へ~
皆さんは、ウイルスや毒素の研究、さらにはワクチン開発など感染症に関わる分野で最も活躍してきた、そして今も活躍していて、10年後も活躍しているであろう培養細胞が日本生まれであることを御存知でしょうか?その細胞は、Vero細胞(ベロ細胞)といいます。
大腸菌O157の生産するベロ毒素Verotoxinという言葉を覚えている方は多いと思いますが、この細菌毒素がこのように名づけられたのはそもそもVero 細胞に対して強い細胞毒性をしめす毒素として発見されたという歴史的経緯によるものです。アフリカミドリザルAfrican green monkeyの摘出腎臓から約半世紀前に樹立されたVero細胞は、微生物学において多大な貢献をしてきただけでなく、さまざまなウイルスワクチンを生産する際に用いる細胞基材として現在でも世界中で最も汎用されている培養細胞です。
私たちは、最近、Vero細胞の全ゲノム配列を決定しました[1](オープンアクセス雑誌に上梓した論文ですのでリンクしました)。
本稿では、Vero細胞の歴史について紹介したのち、Vero細胞のゲノム構造をなぜ明らかにしようとしたのか、そして、決定したゲノム配列からわかってきたこと、さらに、Vero細胞のゲノム構造を基盤にした今後の研究展望について述べたいと思います。
1.日本で生まれたVero細胞
Vero細胞誕生の背景には、1940年代から60年代にかけて世界各地で流行したポリオ(ポリオウイルスによって引き起こされる小児麻痺)をワクチンによって予防しようとした世界的な取り組みがあります。
米国ジョンズ・ホプキンス大学のジョージ・ガイGeorge Geyらによってヒト子宮頸がん生検(バイオプシー、biopsy)サンプルから有名なHeLa細胞が樹立されたのは1951年です[2, 3]。ヒトのような高等動物でも長く継代培養できる細胞株continuous cell linesが得られたことで、その後の実験生命科学は大きく変わってゆきました(培養細胞についての用語説明ページを別に用意しました)。ヒト細胞そのものの性質を実験室レベルでいつでも解析できるようになっただけでなく、それまでなら動物個体や動物からの摘出組織に感染させて増やしていたウイルスを培養皿の中で維持・増殖できる培養細胞を宿主として増やせる道が開けてきたからです。
1950年代はポリオワクチンの開発が成功した時代でもありました。HeLa細胞もポリオの研究に使用されましたが、ワクチンのもととなるポリオウイルスの生産にはサルから摘出した腎臓組織の一次培養細胞primary culture cellsが当時は使用されていました。準備できる細胞の量とウイルス増殖の面からサル腎臓が有利だったのです。何故、サルの腎臓細胞でウイルスが比較的よく増えるのかそのメカニズムは今でも未解明です。
そのような時代背景の中、当時の千葉大学医学部細菌学教室(主任:川喜田愛郎教授)の無給副手であった安村美博(ヤスムラ・ヨシヒロ;後に独協医大微生物学教室教授)は、多くの試行錯誤を忍耐強く行った末にアフリカミドリザルの腎臓から不死化した細胞株cell lineを得ることに成功しました[4, 5]。細胞株の樹立日は、不死化が確認できた日ではなく、その細胞株を得るために最初に組織培養を開始した日と定められており、Vero細胞のその日は1962年3月27日と記録されています[4, 5]。
細菌学教室で樹立されたことから推測できるように、安村先生は微生物研究、特にウイルス研究に有用な培養細胞を得たいという夢をもってこの細胞株の樹立に成功し、その夢に沿うように、Vero細胞はポリオウイルスを含むさまざまな種類のウイルスをよく増やすことのできる細胞であることが樹立後数年以内に明らかになってゆきました。この辺の事情は、安村先生の同僚であった清水文七先生の著書に活写されています[6]。
エスペラント語(世界共通言語として開発された言語であったが今や廃れてしまった感がある)をよくした安村先生は、アフリカミドリザルの腎臓から由来するこの新しい細胞株にエスペラント語で「緑の腎臓」を意味する“Verda Reno”を縮めてVeroという名を与えました。さらに、Veroというスペルがエスペラント語で「真実」(ラテン語ならVeritas)を意味するという卓越したネーミングとなっています(余談1)。
2.何故、私たちはVero細胞の全ゲノム配列を決定しようとしたのか
冒頭に述べたようにVero細胞は感染症関連の研究や検査、そしてワクチン生産と幅広い役割をこの半世紀ずっと人類に対して果たしてきました。本HP原稿を記している2015年の現在、日本で流通しているヒト用ワクチンで、日本脳炎、ロタ、ポリオに対するワクチンはVero細胞を生産細胞に用いています。まだワクチンがないウイルス感染症に関してもVero細胞を利用しながら開発しようとしているものが複数あるようです[7, 8]。
また、高病原性インフルンザ[9]、エボラ出血熱[10]、中東呼吸器症候群(MERS)[11]などの人類を脅かすような新興再興感染症の原因ウイルスを分離・培養するために最初に選択される細胞の一つがVero細胞です。
医薬品生産に使われるような細胞は十分に品質管理がなされる必要があります。細胞の品質管理法はさまざまな手法が確立しており、WHO文書(例えば、TRS_978 Annex1)などにまとめられています。しかし、これら従来の標準的方法は必ずしも科学技術の進歩に追いついてはいません。
特に、ゲノミクスをはじめとするオミックス的な方法論は品質管理手法に取り入れることができるという期待はあるものの、扱うデータが巨大なオミックス手法を国際的な細胞品質管理のガイドラインの中で具体的に規定するにはまだ至っていないようです。しかし、生物学的対象の特性を解析するに当たり、ゲノム情報はもはや不可欠な基盤情報になりつつあるのですから生物学的な医薬品の品質管理にゲノム科学を利用することは止めようのない流れと思われます。
また、従来ほとんどできなかった哺乳動物培養細胞での目的遺伝子特異的な破壊もこの数年間に急速に進歩したゲノム編集技術を用いれば可能になってきています[12]。
私は、体細胞遺伝学的手法を用いた基礎研究に長らく携わっており、感染症対策に資する研究および行政支援活動をする機関の職員としてVero細胞のこともある程度は知っておりました。そして、ゲノム編集技術の培養細胞へ適用は自分たちでやってみても予想していた以上にうまくいくことを経験し[13]、日本生まれのVero細胞の全ゲノム配列を決定して、人類の共通情報資源として提供したいと思い立ちました。
3.多施設共同研究チームの発足
ゲノム科学に不慣れな私がVero細胞の全ゲノム配列を決定したいと思い立って最初に行動したことは、関連する専門家との共同研究チームを作ることです。いくつかの幸運に恵まれて、小人数ながらとても良いメンバーを集めることができました。(独)医薬基盤研究所・細胞資源室の小原室長(以下、小原さん)は、細胞の品質管理の専門家でありますので、ゲノム情報が細胞の品質管理にもつながることに即座に同意し、一緒にやりましょうということになりました。さらに、小原さんの知人で霊長類のゲノム科学に詳しく、カニクイザルMacaca fascicularisの全ゲノム配列決定を成し遂げたこともある長田博士(国立遺伝研究所;2015年4月から北大・情報科学科に異動)(以下、長田さん・オサダさん)を共同研究チームに引き入れてくれました。
目視や顕微鏡観察だけでは見逃しやすい微生物(マイコプラズマや細胞毒性の低いウイルス)のコンタミがないことを確認することが細胞の品質管理には不可欠であり、これを従来のスタンダードである古典的方法で行うのには大変な労力と技術が必要です。
ところで、原因不明の食中毒が発生した場合、食品サンプルの網羅的DNA配列解析をすることで、原因微生物が時間的にも費用的にも格段に効率よく特定できることがあります。DNAシ-ケンサを駆使した感染症疫学検査は私の所属する国立感染症研究所(以下、感染研)においても随時行われており、門前の小僧の如く、私自身もこの方法が培養細胞の微生物混入試験に活用できそうだということには気が付いていました。そこで、このような研究・調査の専門家でもある黒田博士(感染研・病原体ゲノム解析研究センター長)(以下、黒田さん)にも参画を打診し、了承を得ました。
このようにして三つの研究機関の計4グループから成るVero細胞ゲノム配列決定プロジェクト推進チームができたわけです。それぞれのグループが他にはできない専門的技術や知見を出し合い、結局、最後までこの最初の4グループのみで目標に達することができたのですが、どの1グループでも欠けていれば成功は覚束なかったと思われます。
4.シード細胞の選択
ひとくちにVero細胞と言っても世界中で継代されているうちに性質がお互いに少しずつ異なっている亜株(sub-line)が代表的なものでも数株あります。それらのゲノム配列はお互いに大変よく似通っていると推測されるものの、最初に配列決定するにふさわしい亜株はどれだろうと考えました。
単純に考えれば世界の中心的な細胞バンクであるAmerican Type Cell Collection (ATCC)が配布しているVero細胞ATCC CCL81株というのが一番の候補かもしれません。しかし、Vero細胞はもともと日本で樹立された細胞であることから、オリジナルのVero細胞に最も近い、すなわち継代数の少ない保存細胞が国内にあるのではないかと小原さんに調べてもらうと、はたして医薬基盤研・細胞資源室に保管されているものの中にそのようなものがありました。
文献によると、米国の国立アレルギー感染症研究所(National institute of Allergy and Infectious Diseases; NIAID)に継代数93のVero細胞が千葉大学の清水博士によってもち込まれ、113継代目でATCCに寄託されて拡大した121継代目のプールがATCC CCL81株となっています[14]。一方、日本がん研究資源バンク(Japanese Cancer Research Bank; JCRB)にも継代数111の細胞2バイアルが清水博士によって寄託されたという記録があります[15]。この資源バンクはその後いくつかの組織に受け渡されていて、現在は医薬基盤研の管理下になっているのです。そして、111代から培養して増やした継代数115のVero細胞がJCRB0111の登録番号で医薬基盤研に冷凍保存されていました。
JCRBに保存されている継代数111の細胞が米国に最初に渡った継代数93の細胞の直接の子孫にあたるのか、それとも継代数93よりも前に分かれた分家の子孫にあたるのかは今のところはっきりしません。
文献記録の通りにあるべきところにあるべきものがちゃんと存在していたということなのではありますが、それを手繰り寄せるには、「感染症対策に多大な貢献をしてきたVero細胞の最初のゲノム配列決定は是非とも日本チームによって成し遂げたい」という意思が必要であったと思っています。
JCRB0111はおそらく現時点で手に入る最も継代数の少ない、すなわち不死化に成功して細胞株となった当初のVero細胞に一番近いストックです。私たちはこの貴重なストックをVero細胞の全ゲノム配列を最初に決定するシード細胞にすることにしました。
5.核型の解析とは
ゲノム構造の全体像を把握するには、顕微鏡レベルで観察できる染色体chromosomeの様子を把握しておくことも重要です。それには、染色体が凝集して観察しやすい分裂期の細胞を集めて、さらに特殊な操作を加えて染色します(余談2)。
染色体の本数を核型karyotypeと呼びます。ヒトであれば23対の相同染色体(その中の一対は性染色体)から成っており、女性と男性のそれぞれ核型は(46,XX)、(46,XY)と記載されます。
核型を解析するためによく用いられている方法は、古典的ともいえるGiemsa試薬を用いるギムザ・バンド(G-band)法や、よりスマートに各染色体を異なる蛍光色素で染め分ける多色蛍光同所ハイブリダイゼーション(multi-color fluorescence in situ hybridization; M-FISH)法があります。これらは熟練した手技を必要とする方法であり、それぞれに一長一短があります。
Gバンド法は基本的に全ての生物に適応可能です。染色体中にはGiemsa試薬で濃く染まる部分とそうでない部分があってその帯(バンド)のパターンは相同染色体セットの決定や染色体異常を発見する情報にもなります。一方、複数の染色体転座chromosome translocationがあった場合、どの部分がどこへ転座したかをGバンド解析だけで決定するのは困難です。M-FISH法ではそれぞれの染色体を染め分けますので、転座部位がもともとどの染色体にあったのかとか、生物種間の染色体構造保存性(シンテニー、synteny)が一目瞭然になります。一方、染色体ごとに異なる蛍光色素が結合したDNAハイブリダイゼーションプローブのセットが解析対象の生物種で用意されていなければならない点、そして、Gバンド法より高度な技術を要する点はM-FISH法の短所といえましょう。小原グループはその両方に長けており、Vero細胞の実に美しい核型解析データを提供してくれました(図1)。
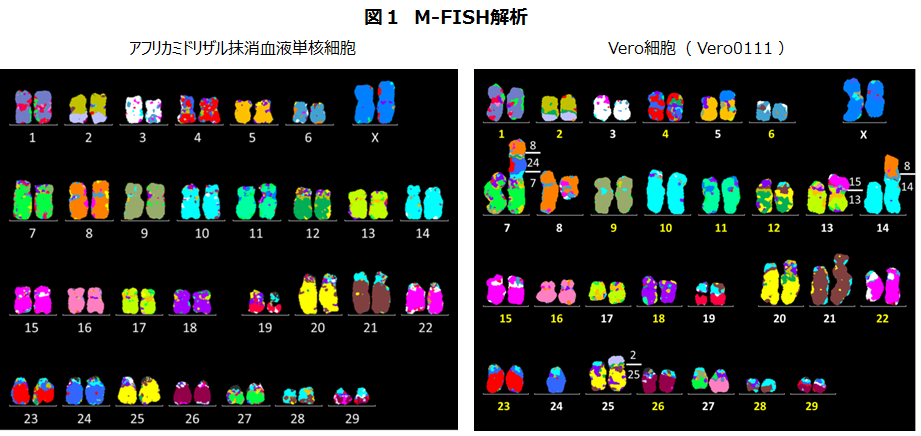
6.アフリカミドリザルの核型とVero細胞の核型
アフリカミドリザルの核型は60本、すなわち29対の常染色体と1対の性染色体から成ります。それに対してVero細胞の核型は59本がメインであり、24番染色体は一見すると一本しかありません。しかし、M-FISHのデータをよくみてみますと、なくなったようにみえた24番染色体は丸ごと7番染色体と結合して存在していることがわかりました(図1)。すなわち、Vero細胞の核型は見かけ上59本であるけれど、遺伝子セットとしてはほぼ二倍体を維持しているということです[1](余談3)。
ところで、昔の論文やATCCのカタログにはVero細胞の核型は58本と記載されております[16]。私たちの核型解析結果59本と差があることの明確な理由は(当初は)不明で、短い大きさの異常染色体を数に含めるかどうかの判断がM-FISHを駆使できる前の時代では難しかったといった技術的な理由によるのかもしれないと推測しました。しかし、その後自分たちでVero ATCC CCL-81株の核型解析をしてみるとカタログ記載通りに58本でした。ATCC CCL-81株では25番染色体の一本が他の染色体と融合しており、そのため染色体数がJCBR0111株よりも一つ少なくなっていることが判明しました(論文作成中)(2017.5.16.本パラグラフ改訂)。